


Finding Top 10 matches from 100 essays
who're my writing soulmates?

Serendipity from writing
In October, I joined a writing bootcamp. The experience was totally beyond my expectations. I never thought social, talking to others, could be a significant part throughout the writing process. Before I often worked in silo from ideation to publishing, but in the course I have engaged with other students at every stage, from clarifying ideas, getting feedback on drafts and sharing polished works.
Many moments of serendipity arose from these interactions. In writing chat rooms, I discovered more than once that my randomly assigned partners were writing about similar ideas. Other times, someone would leave a comment on my essay, saying how they’d been through the same journey. The shared thoughts and experiences, cutting across geographic locations, races or life stages amazed me, making me feel connected to the world.
I can’t help but wonder who else out there thinks and writes like me among writers I haven’t yet met? Rather than relying on the law of chances or waiting for someone to stumble upon my essays, can I look for them proactively? What if I want to find the top 50 writers among my 800 classmates whose work resonates with me? How can I discover my writing soulmates in a more systematic way?
Experiment Design
If I were to manually find the top 50 writing soulmates out of 800, I would have to read all 800 articles and evaluate which one is similar in theme to mine. This sounds like a lot of work and something perfect for automation. Imagine a program that functions like a Google search, using my essay as the query within a pool of 800 essays, ranking the results from the closest match to the least relevant.
When I shared my idea, my GPT friend responded, "you mean calculating cosine similarities between the semantic embeddings of those 800 essays, then sorting and selecting the top 50 matches?"
Yes, that is exactly what I mean. Now explain to me what “semantic embeddings” and “cosine similarities” mean like a 4 year old.

Semantic embeddings
A semantic embedding is a vector-based representation of text generated by a text embedding model.
I used model text-embedding-3-small, a pre-trained model which understands complex language patterns and associations so it’s readily usable for tasks like similarity search, clustering and classification.
Given text as new input to the model, it will encode text to a vector, containing various layers of meanings of the text, such as theme, sentiment, intent, context, structure etc.
Cosine similarities
Essays with similar meanings will have vectors pointing in similar directions in vector space. Cosine similarity measures the angle between two vectors, so it’s commonly used for calculating similarity between two texts.
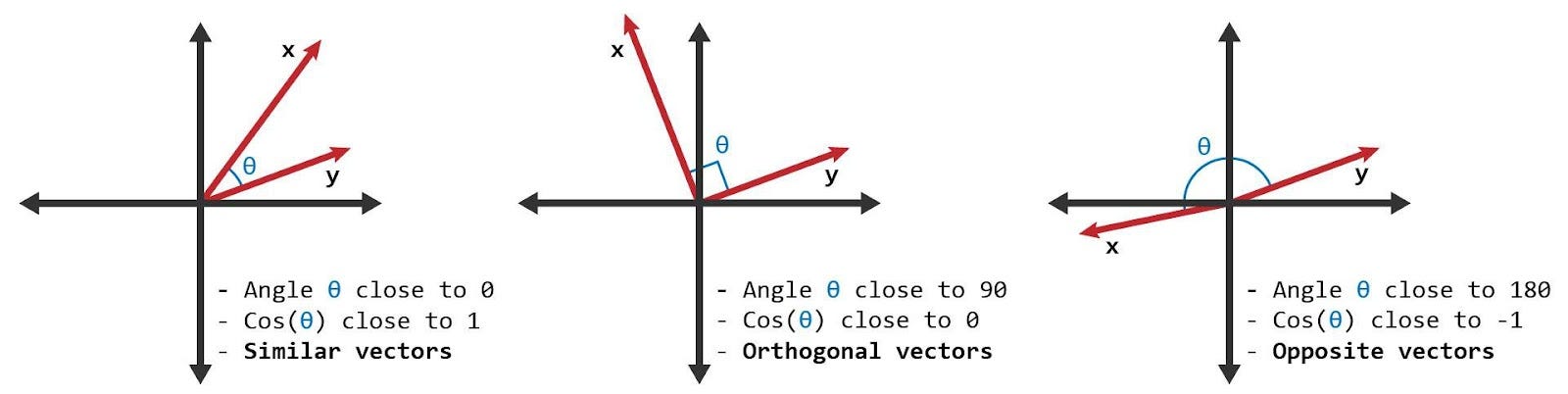
The cosine score ranges from 1 to -1, eg. “car” and “automobile”, almost identical meanings, would have a cosine score close to 1, while “car” and “banana”, not related, would have a score close to 0, and “happy” and “sad” have a score -1 because they are opposite in meaning.
Results
I ended up scraping 100 published essays from my writing class, converted them to semantic embeddings and used my own essay as a query to calculate cosine similarities to each of them. If you are curious about this process, I will link it in a separate article due to email length.
Overall distribution of 82 scores

For semantic embeddings, cosine similarity scores typically range between 0 and 1.
[1 - 0.8]: highly related
[0.8 - 0.5]: similar topics, differ in details
[0.5 - 0]: loosely related themes
Top 10 essays that are semantically close to my writing
the-mind-bin : 0.701
death-fatherhood-and-ayahuasca : 0.676
how-to-walk-to-a-mens-group : 0.668
slow-spaces-for-conversation : 0.661
independence-is-overrated : 0.658
my-lighthouse-to-kindness : 0.653
Finding 1: I’m my own writing soulmate
In the top 10 essays, entry 0 is the query essay, scoring a perfect 1. Interestingly, entry 1 is actually another writing of my own!
My two articles share a similar structure and theme but differ in details. They are both the hero’s journey structure, focusing on getting unstuck in life through self-exploration. They differ in approaches. In the Burning Man article, I got inspiration from the external world, while in the sabbatical essay, I went on an internal journey. Both articles arrive at the same conclusion: I should do work I love, spend time on creative endeavours and make genuine connections with others.
The similarity score of 0.743 feels reasonable because it shows my articles share significant overlap in meaning without being identical. Anything above 0.85 might suggest potential plagiarism. I was initially skeptical about this algorithm, but seeing my other work ranked at the top strongly validated its accuracy for me.
Finding 2 : Common themes in essays but different voices
I quickly reviewed the 10 essays and noticed recurring themes.
The first four essays share stories of life changes, such as moving to a new country, shifting priorities from career to family, leaving a corporate job to become a solopreneur, or sketching plans for retirement. The common thread is a desire to live authentically, even when it comes with opportunity costs.
The next six essays focus on the importance of genuine human connections, like conversation with strangers in third place, third times, in men’s group, in writer’s group, or with friends and families. These scenarios emphasize the joy of connecting genuinely with people and being fully ourselves.
I highly resonate with these writers’ life experiences and thematic focus. An excerpt from
’s essay is a great summary of all [2]:The point is, we’re prone to questioning the legitimacy of our lives and experiences when they defy the established norms, and then step away from who we are, almost dismissing ourselves as an anomaly no one else could relate to.
That is perhaps the momentary birth-point of every writer. The instance in which a person has the thought, “I’m not crazy, I’m just human”—and realizes that’s something worth writing about.”
Beyond the resonance, I find that everyone brings a unique voice even when exploring similar ideas. For instance, when expressing the idea: life is unpredictable, I would never have thought to phrase it as: “the universe is a freight-train of experimentation that we’ll never be able to slow down or derail, no matter how many pennies of thought we place on its tracks”. [2]
Finding 3: the bottom 10 essays
72: the-death-of-serendipity : 0.487
73: micro-moments-a-stepfathers-guide-to-invisible-love : 0.477
74: 9-to-5-perimenopausal-progress : 0.462
75: toxic-humility : 0.458
76: a-sharp-knife-is-all-i-need : 0.450
77: food-doesnt-taste-better-with-friends : 0.433
78: empty-calorie-innovation-is-a-bad : 0.428
79: if-you-want-it : 0.423
80: what-can-we-learn-from-a-race-car-driver-about-business: 0.419
81: product-managers-should-remember : 0.386
82: influencer-marketing-is-emerging : 0.346
To be fair, we should also examine the bottom 10 essays.
The bottom 5 essays are more representative as they all focus on business, finance or marketing areas. Essays 5 - 10 cover broader topics like culture, media, and women’s rights etc, which I rarely talk about in my own writing. I should probably consider adding these subjects into my info diet.
The essays suggested by algorithms are more in the “unrelated” category instead of “opposite” in meaning in relation to my query. However it could be interesting to develop a separate program specifically designed to identify articles with opposite viewpoints to the query.
Future of this project
Use AI to tell me why two essays are similar in what aspects
The result produced by AI is like a black box. I was back reasoning them myself why it picks these articles. I hope it could provide me with explanations on how two articles are similar in what ways.
To peek into the black box, I could do some auxiliary analysis
Ask GPT to explain the result and reverse engineer to repeat the process
use techniques like topic modelling (LDA) or keywords (TF-IDF) to identify similar topics
use hierarchical analysis to identify similar structures
I intend to continue my explorations and automate the explanation part as well. If you are interested, please hit subscribe.
Expand the usage to all Substack articles
Blog/newsletter platforms can use this for recommendation systems, so that when you publish an article, you could get a list of articles with similar (or opposite 😂) meanings.
Substack already incorporates a similar feature; when you post a note, it suggests streams of related notes.

References
Zoumana Keita’s illustration: https://www.datacamp.com/tutorial/exploring-text-embedding-3-large-new-openai-embeddings
Great essay from Rick that I quoted several times in the article: The Antidote to Writer's Block is Friendship
Appendix
Execution
Step 1 Get all published links from assignment 2
After inspecting the network tab of https://home.writeofpassage.school/c/published-2-c13/, I found Circle's API for retrieving the list of posts within a space. The response payload included all posts, from which I extracted the article link for each. In total, there are about 99 links to published articles.

Step 2 Scrape articles
I sent HTTP requests to each article link and received the HTML pages, then extracted the text in <p> tags. This method yielded 82 meaningful results, as HTTP requests only retrieve HTML or JSON. If an article relies on JavaScript to render in the browser, I couldn't scrape it. A better approach would be to use a tool that can capture dynamically loaded content.

The last 2 essays are mine. I included my essay from assignment 1 as well.
Step 3 Convert articles to semantic embeddings
In this step, I used OpenAI’s “text-embedding-3-small” model to generate semantic embeddings for each of the 82 essays. This model is pre-trained on a large corpus to understand language and semantic relationships across words, sentences, and even longer passages. For each article input, the model generated a vector of 1,536 floating-point numbers, capturing the text's nuanced features in syntax, semantics, and context.

As a result, I've transformed the text of each article into 82 vectors of numbers.
Step 4 Calculating similarities and Find top 10 matches!
Two articles on similar topics will have embeddings that are closer in vector space, meaning their semantic content is more aligned. Cosine similarity quantifies the closeness by measuring the angle between two vectors regardless of their magnitude.Then I could identify the top 10 articles by sorting the similarity scores in descending order.
After all the data wrangling, the magic moment finally arrives.
Wow, I've never seen anything like this before Chenshu. A masterpiece. Though calling it that feels like describing a sunset as 'nice.' Reading this gave me the odd feeling that somewhere out there, my essays might be silently plotting their escape to find their soulmates too. Makes me wonder—what would an essay classified as my 'polar opposite' even look like? Would it be The Bagels That Were Never Lost?